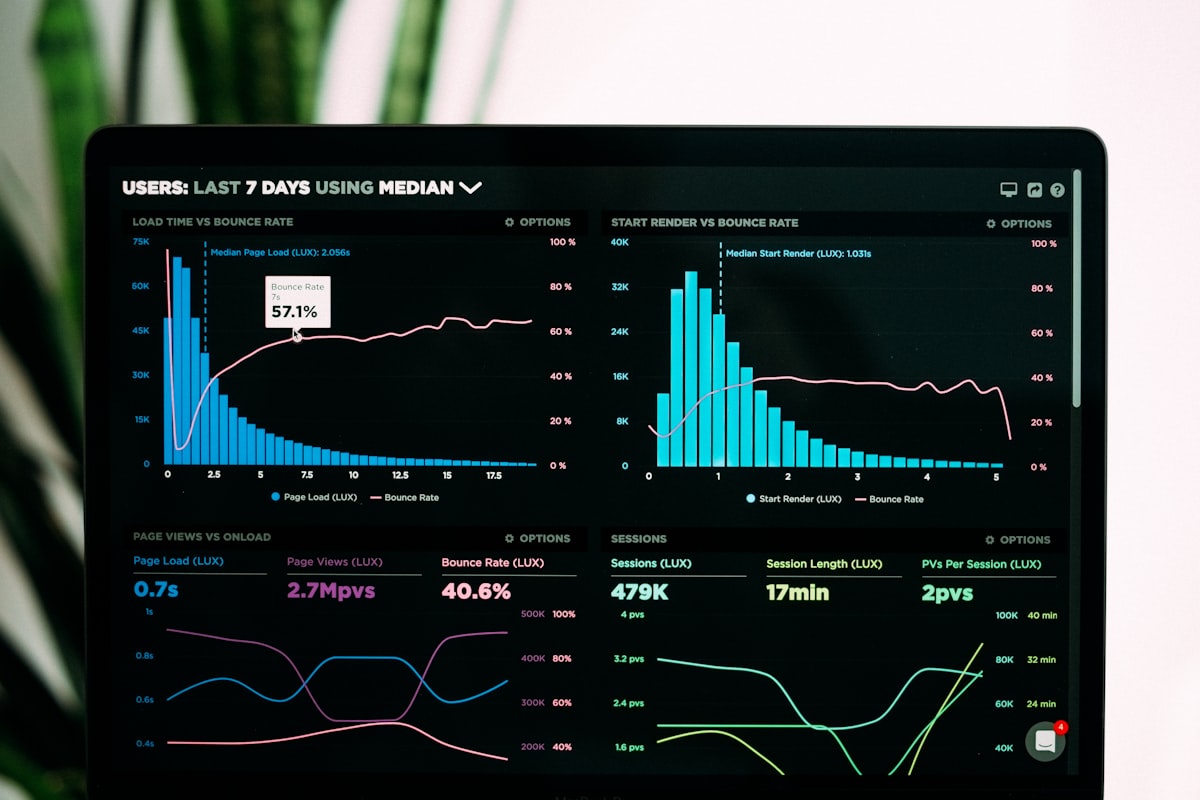
52% der KI-Agent-Teams haben Evaluierungstools im Einsatz. Diese Zahl stammt aus LangChains State of AI Agents Umfrage unter 1.300+ Fachleuten. Qualität wurde als größtes Produktionshindernis genannt (32%), während Observability-Tools bereits bei 89% Adoption liegen. Die Diskrepanz ist aufschlussreich: Teams wissen, dass sie ihre Agenten überwachen müssen. Aber den meisten fehlt eine strukturierte Methode, um zu messen, ob die Agenten korrekt funktionieren.
Der Markt hat reagiert. Zwischen Ende 2025 und Anfang 2026 hat Maxim AI eine Agent-Simulation ausgeliefert, Langfuse sein komplettes Feature-Set unter MIT-Lizenz gestellt, Braintrust die automatisierte “Loop”-Analyse gestartet, und Arize Phoenix Multi-Step-Agent-Trace-Evaluierung hinzugefügt. Confident AIs DeepEval-Framework bietet mittlerweile über 50 Metriken. Die Frage ist nicht mehr, ob man Agenten evaluieren soll. Sondern welche Plattform die richtige ist.
Warum Agent-Evaluierung grundlegend anders ist als LLM-Evaluierung
Einen einzelnen LLM-Aufruf zu evaluieren ist überschaubar: Prompt rein, Antwort raus, Antwort prüfen. Agent-Evaluierung ist ein völlig anderes Problem.
Ein Agent, der einen Flug buchen soll, ruft möglicherweise eine Such-API auf, filtert Ergebnisse, wählt eine Option aus, füllt ein Formular aus, bestätigt beim Nutzer und führt eine Zahlung durch. Ein Fehler in Schritt fünf kann von einer falschen Entscheidung in Schritt zwei stammen. Das Evaluierungstool muss den gesamten Ausführungspfad erfassen, nicht nur das Endergebnis.
Drei Fähigkeiten unterscheiden Agent-Eval-Tools von einfacher LLM-Evaluierung:
Multi-Step-Trace-Erfassung. Jeder Tool-Aufruf, jede LLM-Anfrage, jeder Retrieval-Schritt und jede Entscheidung muss mit vollem Kontext protokolliert werden. Ohne das ist Agent-Debugging Ratespiel.
Trajectory-Evaluierung. Nur das Endergebnis zu bewerten reicht nicht. Man muss Zwischenschritte bewerten: Hat der Agent die richtigen Tools in der richtigen Reihenfolge aufgerufen? Hat er Grenzfälle in jedem Schritt behandelt? Confident AI nennt das “Step-Level Evaluation”, und es verändert grundlegend, welche Fehler man finden kann.
Zustandsbasierte Testszenarien. Agenten interagieren mit Datenbanken, APIs und Nutzersitzungen. Die Eval-Suite muss realistischen Zustand aufsetzen (Mock-Datenbanken, API-Fixtures, Gesprächsverläufe) und verifizieren, dass der Agent diesen Zustand korrekt verändert hat. Sierras Tau-Bench bewertet Agenten danach, ob sie den korrekten Datenbankzustand erreicht haben, nicht danach, ob das Gespräch gut klang.
Fünf Plattformen im direkten Vergleich
Maxim AI: Die All-in-One-Simulationsmaschine
Maxim positioniert sich als End-to-End-Plattform, die Prompt-Engineering, Agent-Simulation, Evaluierung und Produktionsmonitoring in einem Tool vereint.
Was heraussticht: Maxims Simulationsengine kann Tausende von Agent-Szenarien durchspielen, bevor man in Produktion geht. Man definiert Nutzerpersonas, Gesprächsabläufe und Grenzfälle. Maxim generiert synthetische Testsitzungen und bewertet die Ergebnisse mit einer Bibliothek vorgefertigter Evaluatoren (LLM-as-Judge, statistisch, programmatisch) oder eigenen Scorern. Das Prompt-CMS ermöglicht Versionierung und Verwaltung von Prompts außerhalb der Codebasis.
Das Gateway-Modell: Maxims Bifrost-Gateway bietet eine einzige OpenAI-kompatible API für über 1.000 Modelle mit automatischem Failover, Load Balancing, semantischem Caching und Budget-Management. Wer LLM-Aufrufe über Bifrost routet, bekommt Traces automatisch erfasst, ohne Instrumentierungscode.
Preise: Kostenloser Einstiegstarif verfügbar. Bezahlpläne nur auf Anfrage.
Am besten für: Teams, die Simulation, Evaluierung und Observability unter einem Dach wollen und bereit sind, Maxims Gateway als LLM-Zugangslayer zu nutzen.
Langfuse: Open-Source-Kontrolle mit Enterprise-Reichweite
Langfuse hat Mitte 2025 einen entscheidenden Schritt gemacht: Das Team hat jedes Produktfeature unter MIT-Lizenz gestellt. LLM-as-Judge-Evaluierungen, Annotation-Queues, Prompt-Experimente, der Playground, alles frei verfügbar. Im Januar 2026 wurde Langfuse von ClickHouse übernommen, was ernsthafte Datenbank-Infrastruktur hinter die Plattform brachte.
Was heraussticht: 23.000+ GitHub-Stars und Einsatz bei 19 der Fortune 50. Langfuse deckt Tracing, Prompt-Management, Evaluierungen und Datasets ab. Man kann den gesamten Stack selbst hosten (kein Vendor Lock-in) oder die Managed Cloud nutzen. Multi-Turn-Conversation-Support, Prompt-Versionierung mit Trace-Verknüpfung und Performance-Vergleiche vor und nach Prompt-Deployments sind inklusive.
Der Kompromiss: Langfuse selbst zu hosten bedeutet, ClickHouse- und PostgreSQL-Infrastruktur zu betreiben. Für Unternehmen mit Plattform-Team kein Problem. Für ein 5-Personen-Startup ist der Betriebsaufwand real. Die Managed Cloud (ab 29 $/Monat) eliminiert das. Langfuse bietet außerdem weder Braintrusts automatisierte Log-Analyse (“Loop”) noch eingebaute Drift-Erkennung.
Preise: Cloud ab 29 $/Monat. Self-Hosted kostenlos (MIT-Lizenz), keine Nutzungslimits.
Am besten für: Teams mit strikten Datenschutzanforderungen (DSGVO), Open-Source-Vorgaben oder der Infrastruktur-Kompetenz für Self-Hosting. Besonders relevant für Unternehmen im DACH-Raum, wo Datenhoheit häufig Pflicht ist.
Braintrust: Eval-First mit integriertem Produktionsmonitoring
Braintrust wurde um einen spezifischen Workflow herum gebaut: Evals ausführen, Ergebnisse vergleichen, in Produktion bringen, dann überwachen. Alles verbindet sich über Traces.
Was heraussticht: Braintrust erfasst jeden LLM-Aufruf, jeden Tool-Call und jeden Retrieval-Schritt automatisch. Das “Loop”-Feature nutzt KI, um Produktionslogs zu analysieren und Muster aufzudecken, die menschlichen Reviewern entgehen. Zum Beispiel eine bestimmte Tool-Call-Sequenz, die mit Nutzerbeschwerden korreliert. Der Eval-Runner integriert sich direkt in CI/CD und führt Evaluierungen bei jedem Pull Request aus. TypeScript/JavaScript-Support ist erstklassig, kein Nachgedanke.
Die Zahlen: Der kostenlose Tarif umfasst 1 Million Trace-Spans pro Monat, unbegrenzte Nutzer und 10.000 Evaluierungsläufe. Pro startet bei 249 $/Monat. Setup dauert etwa 30 Minuten.
Der Kompromiss: Nicht Open Source. Wenn Datenhoheit zwingend ist, braucht man die Enterprise-Self-Hosting-Option (Preis nicht öffentlich). Die Plattform ist für Teams optimiert, die einen vordefinierten Workflow wollen. Wer lieber eigene Evaluierungspipelines baut, könnte sich eingeengt fühlen.
Am besten für: Produkt-Engineering-Teams, die Eval und Monitoring in einem Tool wollen, mit starker CI/CD-Integration und einer Präferenz für verwaltete Infrastruktur.
Arize Phoenix: Open-Source-Agent-Tracing mit Forschungstiefe
Arize bietet zwei Produkte: Phoenix (Open Source, Self-Hosted) und Arize AX (Enterprise SaaS). Phoenix hat sich als Standard für Open-Source-Agent-Observability mit tieferen Evaluierungsfähigkeiten als Langfuse etabliert.
Was heraussticht: Phoenix erfasst vollständige Multi-Step-Agent-Traces und unterstützt strukturierte Evaluierungsworkflows. Eingebaute Drift-Erkennung, Embedding-Analyse für Retrieval-Qualität und detaillierte Span-Level-Inspektion sind dabei. Das Evaluierungs-Framework unterstützt sowohl automatisierte Metriken als auch Human-Annotation-Workflows. Phoenix schlägt außerdem die Brücke zwischen klassischem ML-Monitoring (Data Drift, Feature Importance) und LLM-spezifischer Evaluierung.
Der Kompromiss: Phoenix’ Stärke ist Observability mit angeschlossener Evaluierung. Es erreicht weder Maxims Simulationsfähigkeiten noch Braintrusts CI/CD-Integrationstiefe. Die Enterprise-AX-Plattform ergänzt diese Features, führt aber aus dem Open-Source-Bereich heraus.
Am besten für: Data-Science-Teams mit bestehenden ML-Monitoring-Anforderungen, die Agent-Evaluierung hinzufügen, oder Teams, die Open-Source-Tracing mit mehr Evaluierungstiefe als Langfuse wollen.
Confident AI (DeepEval): Die Metriken-Bibliothek
Confident AI geht einen anderen Weg: Statt auf Tracing aufzubauen, stellt es Evaluierungsmetriken in den Vordergrund. DeepEval, ihr Open-Source-Framework, liefert über 50 forschungsbasierte Metriken ab Werk.
Was heraussticht: DeepEval evaluiert jeden Schritt der Agent-Ausführung separat: Tool-Aufrufe, Reasoning, Retrieval, Planung. Die Plattform bietet Graph-Visualisierung zum Debugging von Ausführungspfaden, Multi-Turn-Agent-Simulation und übergreifende Workflows, bei denen Produktmanager und QA-Ingenieure neben Entwicklern an Qualitätsmetriken arbeiten. Alle Evaluierungsszenarien (RAG, Agenten, Chatbots, Single-Turn, Multi-Turn, Safety) werden in einem Framework abgedeckt.
Der Kompromiss: Confident AIs Observability-Features sind dünner als bei Braintrust oder Langfuse. Wer Produktionsmonitoring neben Evaluierung braucht, wird DeepEval wahrscheinlich mit einem separaten Tracing-Tool kombinieren. Die Plattform ist neuer und hat eine kleinere Community als Langfuse oder Arize.
Am besten für: Teams, die Evaluierungstiefe über Observability-Breite priorisieren, besonders bei komplexen Multi-Step-Agenten, wo Step-Level-Metriken wichtiger sind als aggregierte Scores.
Die Vergleichstabelle
| Feature | Maxim AI | Langfuse | Braintrust | Arize Phoenix | Confident AI |
|---|---|---|---|---|---|
| Open Source | Nein | Ja (MIT) | Nein | Ja (Phoenix) | Ja (DeepEval) |
| Self-Hosting | Nein | Ja | Nur Enterprise | Ja | Ja |
| Agent-Trace-Erfassung | Via Bifrost Gateway | SDK-Instrumentierung | Auto-Capture | SDK-Instrumentierung | SDK-Instrumentierung |
| Multi-Step-Eval | Ja (Simulation) | Basis | Ja (Trajectory) | Ja (Spans) | Ja (Step-Level) |
| LLM-as-Judge | Ja | Ja | Ja | Ja | Ja (50+ Metriken) |
| CI/CD-Integration | API-basiert | API-basiert | Nativ (PR-Evals) | API-basiert | pytest-Plugin |
| Prompt-Management | Ja (CMS + IDE) | Ja (Versionierung) | Ja (Playground) | Nein | Nein |
| Drift-Erkennung | Nein | Nein | Via Loop AI | Ja (eingebaut) | Nein |
| Kostenloser Tarif | Ja | Ja (Cloud ab 29 $) | 1M Spans/Monat | Kostenlos (Self-Host) | Kostenlos (Self-Host) |
| Bezahltarif ab | Auf Anfrage | 29 $/Monat | 249 $/Monat | Auf Anfrage | Auf Anfrage |
Die richtige Plattform finden
Feature-Vergleiche auf dem Papier helfen nur bedingt. Drei Fragen bestimmen die Entscheidung.
Frage 1: Müssen Daten im eigenen Haus bleiben?
Wenn Regulierung, DSGVO-Compliance oder Unternehmensrichtlinien verlangen, dass Telemetriedaten die eigene Infrastruktur nicht verlassen, reduziert sich die Auswahl auf Langfuse (MIT, vollständiges Self-Hosting), Arize Phoenix (Open Source, Self-Hosting) oder Confident AIs DeepEval (Open-Source-Framework). Maxim und Braintrust bieten Enterprise-Self-Hosting an, allerdings zu nicht öffentlichen Preisen.
Für Teams in DSGVO-regulierten Umgebungen oder mit sensiblen Daten ist Self-Hosting keine Option, sondern Pflicht. Langfuses ClickHouse-Fundament (verstärkt durch die Übernahme) macht es zur produktionsreifsten Self-Hosting-Lösung.
Frage 2: Ist Evaluierung oder Observability die primäre Lücke?
Wenn Agenten bereits in Produktion laufen und Monitoring der erste Bedarf ist, sind Braintrust oder Langfuse die stärkeren Startpunkte. Beide erfassen Produktionstraces und ermöglichen den Aufbau von Eval-Datasets aus echtem Traffic.
Wer vor dem Produktionsstart steht und Tausende Testszenarien simulieren muss, findet in Maxims Simulationsengine ein spezialisiertes Werkzeug. Wer die tiefsten Evaluierungsmetriken für komplexe Multi-Step-Agenten braucht, bekommt mit Confident AIs DeepEval die granularste Step-Level-Analyse.
Frage 3: Wie sieht der Stack aus?
LangChain/LangGraph-Teams sollten LangSmith ernsthaft in Betracht ziehen, das hier nicht im Vergleich steht, weil es weniger eine allgemeine Eval-Plattform ist als vielmehr eine native Erweiterung des LangChain-Ökosystems. Wer bereits LangChain nutzt, braucht für LangSmith nur eine einzige Umgebungsvariable.
TypeScript-lastige Teams tendieren zu Braintrust (erstklassiger TS-Support). Python-lastige Teams haben die größte Auswahl. Teams mit bestehendem ML-Monitoring auf Arize sollten mit Phoenix starten, um Tooling zu konsolidieren.
Der praktische Einstieg
Nicht die Plattform wählen und jedes Feature nutzen wollen. Mit einem Workflow starten.
Langfuse oder Braintrusts SDK installieren. Den Einstiegspunkt des Agenten instrumentieren. 20 reale Testfälle durchlaufen lassen (aus Produktionsvorfällen oder Kundenbeschwerden gezogen, nicht synthetische Happy Paths). Einen LLM-as-Judge-Evaluator für die wichtigste Qualitätsdimension einrichten. Diese Evaluierung bei jeder Code-Änderung ausführen.
Diese eine Schleife, Trace-Evaluieren-Vergleichen-Ausliefern, zeigt nach zwei Wochen mehr über den tatsächlichen Bedarf als jeder Feature-Vergleich. Dann weiß man, ob Simulation (Maxim), tiefere Metriken (Confident AI), Drift-Erkennung (Arize) oder das aktuelle Tool ausreichen.
Die 48% der Teams ohne Evaluierungstooling verpassen nicht nur ein Tool. Sie liefern Agenten aus, ohne zu wissen, ob diese funktionieren. Genau diese Lücke schließen diese Plattformen.
Häufig gestellte Fragen
Was sind die besten KI-Agent-Evaluierungstools 2026?
Die führenden KI-Agent-Evaluierungsplattformen 2026 sind Maxim AI (End-to-End-Simulation und Evaluierung), Langfuse (Open Source unter MIT-Lizenz mit 23.000+ GitHub-Stars, von ClickHouse übernommen), Braintrust (Eval-First mit CI/CD-Integration, kostenloser Tarif mit 1M Trace-Spans/Monat), Arize Phoenix (Open Source mit eingebauter Drift-Erkennung) und Confident AIs DeepEval (50+ forschungsbasierte Evaluierungsmetriken). LangSmith wird außerdem häufig von Teams im LangChain-Ökosystem eingesetzt.
Ist Langfuse kostenlos und Open Source?
Ja. Seit Mitte 2025 sind alle Langfuse-Produktfeatures MIT-lizenziert und kostenlos selbst zu hosten, ohne Nutzungslimits. Das umfasst LLM-as-Judge-Evaluierungen, Annotation-Queues, Prompt-Experimente und den Playground. Der Managed-Cloud-Service startet bei 29 $/Monat. Langfuse wurde im Januar 2026 von ClickHouse übernommen, was Enterprise-Grade-Datenbank-Infrastruktur hinter die Plattform brachte.
Wie unterscheidet sich KI-Agent-Evaluierung von LLM-Evaluierung?
LLM-Evaluierung prüft ein einzelnes Input-Output-Paar. Agent-Evaluierung muss Multi-Step-Ausführungstraces (Tool-Aufrufe, Retrieval, Reasoning-Ketten) behandeln, Zwischenentscheidungen bewerten und verifizieren, dass der Agent externen Zustand korrekt verändert hat (Datenbanken, APIs, Nutzersitzungen). Das erfordert Trajectory-Evaluierung, Step-Level-Metriken und zustandsbasierte Testszenarien, die generische LLM-Eval-Tools nicht unterstützen.
Was ist der Unterschied zwischen Braintrust und Langfuse?
Braintrust ist eine verwaltete SaaS-Plattform mit Fokus auf Eval-plus-Monitoring mit nativer CI/CD-Integration, automatisierter Log-Analyse (Loop) und starkem TypeScript-Support. Der kostenlose Tarif umfasst 1M Trace-Spans pro Monat, Pro ab 249 $/Monat. Langfuse ist MIT-lizenziert, Open Source mit vollem Self-Hosting, Prompt-Versionierung und Multi-Turn-Conversation-Support. Cloud ab 29 $/Monat. Braintrust für verwalteten, strukturierten Workflow; Langfuse für Datenhoheit oder Open-Source-Kontrolle.
Wie starte ich mit der Evaluierung meiner KI-Agenten?
Mit dem SDK einer Eval-Plattform starten (Langfuse oder Braintrust sind gute Einstiegspunkte). 20 Testfälle aus echten Produktionsvorfällen oder Kundenbeschwerden sammeln. Einen LLM-as-Judge-Evaluator für die wichtigste Qualitätsdimension einrichten. Diese Evaluierung bei jeder Code-Änderung ausführen. Diese Trace-Evaluieren-Vergleichen-Ausliefern-Schleife zeigt nach zwei Wochen mehr über den tatsächlichen Bedarf als jeder Feature-Vergleich.