57,3% der Teams, die KI-Agenten bauen, haben sie produktiv im Einsatz. Das ist das zentrale Ergebnis von LangChains State of Agent Engineering Survey, einer Befragung von 1.340 Entwicklern, Produktmanagern und Führungskräften zwischen November und Dezember 2025. Die Zahl allein ist nicht die Geschichte. Die Geschichte steckt in dem, womit diese Teams nach dem Deployment kämpfen.
Qualität bleibt die Hauptbarriere (32%). Latenz ist als neues Problem aufgetaucht. Und die aufschlussreichste Statistik: 89% der Teams haben Observability implementiert (sie sehen, was ihre Agenten tun), aber nur 52% führen Evaluierungen durch (sie prüfen, ob das Ergebnis korrekt war). Die Teams beobachten ihre Agenten genau, überspringen aber den Teil, in dem sie die Ergebnisse bewerten.
Wer hat geantwortet und warum das relevant ist
Die Umfrage bildet ein spezifisches Segment ab: Teams, die bereits aktiv bauen. 63% arbeiten im Technologiesektor, 10% in Finanzdienstleistungen, 6% im Gesundheitswesen. Knapp die Hälfte (49%) kommt aus Unternehmen mit weniger als 100 Mitarbeitern, 18% aus Organisationen mit über 2.000 Beschäftigten. Das ist keine Zufallsstichprobe aller Unternehmen, sondern ein Querschnitt der aktiven Builder-Community, was die Ergebnisse für Praktiker wertvoller macht.
Für Großunternehmen ergibt sich ein klares Bild: 67% der Organisationen mit über 10.000 Mitarbeitern haben Agenten in Produktion, verglichen mit 50% bei kleineren Firmen. Aber kleinere Unternehmen holen auf. 36% der Sub-100-Mitarbeiter-Teams entwickeln aktiv mit konkreten Deployment-Plänen, verglichen mit 24% bei Großkonzernen. Kleinere Teams sind schneller. Größere Teams haben mehr Agenten bereits im Einsatz.
Diese Zahlen stimmen mit dem G2 Enterprise AI Agents Report überein, der unabhängig ebenfalls 57% Produktionsadoption fand. Wenn zwei unterschiedliche Umfragen auf fast dieselbe Zahl kommen, ist das Signal belastbar.
Was die Teams bauen: Coding-Agenten dominieren den Alltag
Die offiziellen Use-Case-Rankings setzen Recherche und Zusammenfassung auf Platz eins (58%), persönliche Produktivität auf Platz zwei (53,5%) und Kundenservice auf Platz drei (45,8%). Die aufschlussigeren Daten kommen aber aus den Freitextantworten, in denen Befragte beschrieben, welche Agenten sie täglich nutzen.
Coding-Agenten dominierten. Claude Code, Cursor, GitHub Copilot, Amazon Q, Windsurf. Diese Tools tauchten deutlich häufiger auf als jeder Enterprise-Use-Case. Recherche-Agenten (ChatGPT, Claude, Gemini, Perplexity) folgten auf Platz zwei. Individuelle interne Agenten auf Basis von LangChain und LangGraph kamen an dritter Stelle, für alles von QA-Testing bis Text-to-SQL bis Demand Planning.
Das zeigt eine Kluft zwischen dem, was Unternehmen offiziell deployen, und dem, worauf einzelne Entwickler wirklich angewiesen sind. Der genehmigte Enterprise-Agent bearbeitet Kundenanfragen. Der Coding-Agent, der jedem Entwickler zwei Stunden am Tag spart, taucht in keiner offiziellen Projektliste auf. Deloittes State of AI in the Enterprise Report bestätigt dieses Muster: 60% der Arbeitnehmer haben mittlerweile Zugang zu genehmigten KI-Tools, gegenüber unter 40% ein Jahr zuvor. Die ungenehmigten Tools sind schwerer zu zählen.
Primäre Einsatzfelder nach Use Case
Wenn Teams einen einzigen Haupt-Use-Case nennen, verschiebt sich die Rangfolge:
- Kundenservice: 26,5% (Triage, Lösung, Beschleunigung der Antwortzeiten)
- Recherche und Datenanalyse: 24,4%
- Interne Workflow-Automatisierung: 18%
Für Konzerne mit über 10.000 Mitarbeitern steht interne Produktivität an erster Stelle (26,8%), gefolgt von Kundenservice (24,7%). Großunternehmen automatisieren zuerst interne Abläufe, dann kundenorientierte Workflows. Das ergibt Sinn: Interne Fehler sind billiger als kundenorientierte.
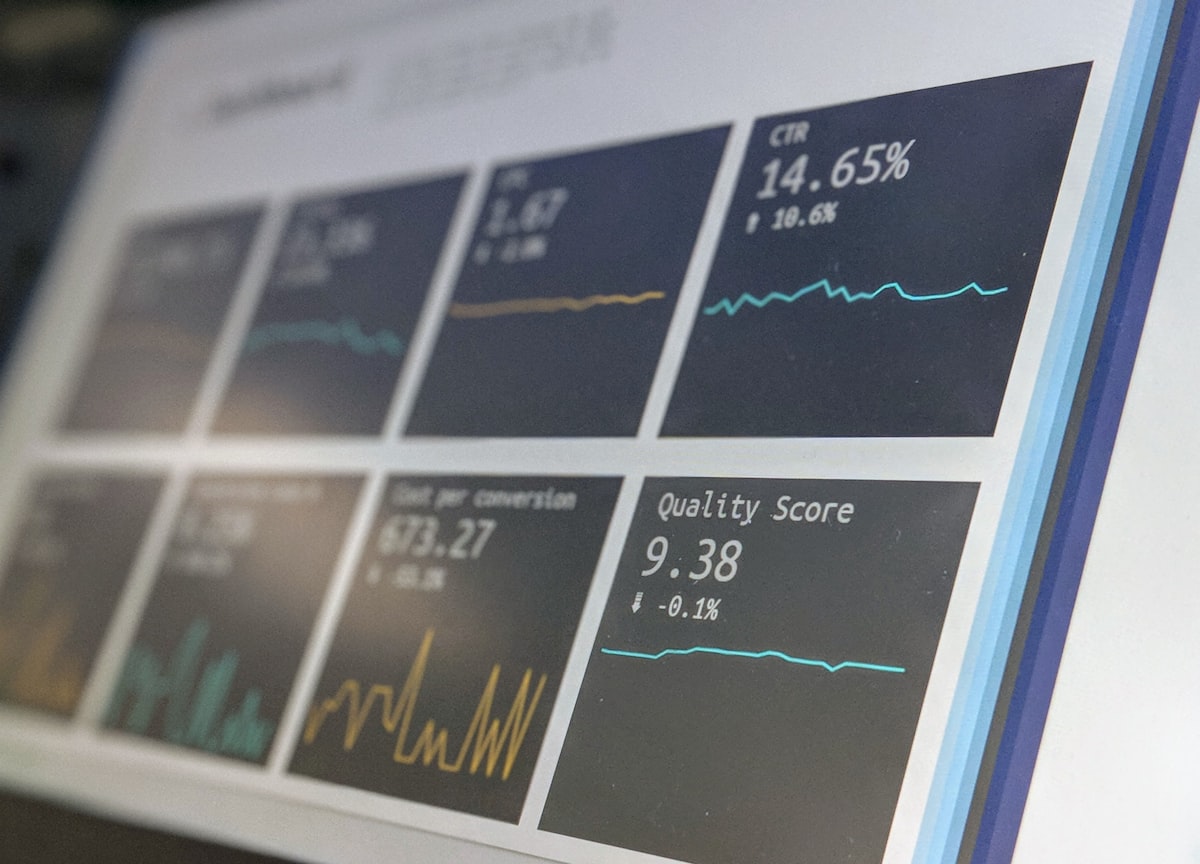
Die Observability-Evaluierungs-Lücke
Dieses Ergebnis sollte Engineering-Verantwortliche aufhorchen lassen. Agent-Observability ist fast universell: 89% der Teams haben irgendeine Form implementiert, 62% verfügen über detailliertes Tracing mit Einblick in einzelne Agentenschritte und Tool-Aufrufe. Bei Teams, die bereits in Produktion sind, steigen diese Zahlen auf 94% und 71,5%.
Aber Evaluierung, die Praxis des systematischen Testens, ob Agenten korrekte Ergebnisse liefern, hinkt deutlich hinterher. Nur 52,4% führen Offline-Evaluierungen an Testdatensätzen durch. Nur 37,3% betreiben Online-Evaluierung zur Überwachung der Echtzeit-Performance. Und 29,5% evaluieren überhaupt nicht, eine Zahl, die bei Produktionssystemen auf 22,8% sinkt, aber immer noch erschreckend hoch ist.
Die Lücke ist nachvollziehbar. Observability beantwortet “Was hat der Agent getan?” Evaluierung beantwortet “War das die richtige Aktion?” Die erste Frage ist einfacher zu instrumentieren. Die zweite erfordert eine Definition von “richtig” für den spezifischen Anwendungsfall, was bei nicht-deterministischen Systemen genuin schwierig ist.
Wie Teams evaluieren (wenn sie es tun)
Unter den Teams, die evaluieren, sind die Methoden aufschlussreich:
- Menschliche Überprüfung: 59,8% (nach wie vor die vertrauenswürdigste Methode)
- LLM-als-Richter: 53,3% (ein Modell bewertet die Ausgabe eines anderen)
- Klassische ML-Metriken (ROUGE/BLEU): geringe Verbreitung
Etwa 25% der evaluierenden Teams nutzen sowohl Offline- als auch Online-Ansätze, was dem Goldstandard entspricht. Der Rest teilt sich zwischen einem der beiden Ansätze auf. Die LLM-als-Richter-Adoption bei 53,3% zeigt, dass KI zur Bewertung von KI zum Mainstream geworden ist, auch wenn die Methodik noch verfeinert wird.
Qualität, Latenz und das schwindende Kostenproblem
Die Barrieren-Landschaft hat sich seit der vorjährigen Umfrage spürbar verschoben.
Qualität bei 32% bleibt der größte Blocker. Halluzinationen und inkonsistente Ausgaben werden besonders von Enterprise-Befragten genannt. Das passt zu Gartners Prognose, dass über 40% der 2025 gestarteten Agentic-AI-Projekte bis 2027 eingestellt werden, hauptsächlich wegen Qualitäts- und Vertrauensproblemen.
Latenz bei 20% ist der Neueinsteiger. Sobald Agenten von Demos zu Produktions-Workflows wechseln, in denen Nutzer auf Antworten warten, wird Geschwindigkeit entscheidend. Ein Recherche-Agent mit 45 Sekunden Antwortzeit ist akzeptabel. Ein Kundenservice-Agent mit 45 Sekunden verliert den Kunden.
Sicherheit steigt bei Enterprises auf Platz zwei (24,9%). Die Realität ist: Agenten Zugriff auf Produktionssysteme zu geben, vergrößert die Angriffsfläche. Für DACH-Unternehmen, die gleichzeitig DSGVO und den EU AI Act einhalten müssen, verschärft sich dieses Problem zusätzlich.
Kosten bei 18,4% sind deutlich gesunken. Preissenkungen bei OpenAI, Anthropic und Open-Source-Alternativen haben den Druck genommen. Das ist eine der wenigen uneingeschränkt positiven Entwicklungen: Die Technologie wird schnell genug günstiger, dass Kosten zur Nebensache werden.
Frameworks und Modelle: Multi-Everything als Standard
75%+ der Teams nutzen mehrere Modelle. OpenAI führt mit 67%+ Adoption, aber Claude, Gemini und Open-Source-Modelle haben signifikante Verbreitung. 33% der Teams investieren in selbst gehostete und Open-Source-Modellinfrastruktur, und 57% setzen auf Basismodelle mit Prompt Engineering und RAG statt auf Fine-Tuning.
Auf der Framework-Seite zeigt die Umfrage LangGraph als populärstes Low-Level-Orchestrierungs-Framework mit 12 Millionen monatlichen Downloads und Produktionseinsätzen bei Uber, Klarna, LinkedIn und J.P. Morgan. CrewAI nennt 60% der Fortune-500-Unternehmen und über 100.000 tägliche Agenten-Ausführungen. Microsoft hat AutoGen und Semantic Kernel zu einem einheitlichen Agent Framework zusammengeführt.
LangChains eigenes Team war erfrischend direkt: “Benutzt LangGraph für Agenten, nicht LangChain.” Die ursprüngliche LangChain-Bibliothek ist der Einstiegspunkt. LangGraph ist das Produktionstool.
Enterprise-Berechtigungsmuster
Die Umfrage offenbarte einen interessanten Split bei Agent-Berechtigungen. Größere Unternehmen (ab 2.000 Mitarbeiter) setzen stark auf Read-Only-Berechtigungen: Agenten dürfen Informationen abrufen und analysieren, aber keine Aktionen ausführen. Kleinere Unternehmen priorisieren Tracing und schnelle Iteration, gewähren Agenten Schreibzugriff, instrumentieren aber alles, was sie tun.
Das passt zum Befund, dass Sicherheit für Enterprises ein Top-2-Thema ist. Wenn ein Agent Salesforce-Daten lesen, aber nicht ändern kann, ist der Blast Radius eines Fehlers begrenzt. Für Unternehmen im DACH-Raum, die den EU AI Act einhalten müssen, ist die Frage der Agent-Berechtigungen nicht optional: Artikel 14 verlangt menschliche Aufsicht für Hochrisiko-KI-Systeme.
Was das für 2026 bedeutet
Die LangChain-Umfrage bildet ein Feld ab, das die Hype-Phase hinter sich hat und in der “tatsächlich Dinge bauen”-Phase steckt. Die 57,3% Produktionsquote ist real, durch unabhängige Umfragen bestätigt und wachsend. Aber die Qualitätsbarriere bei 32%, die Evaluierungslücke (89% Observability vs. 52% Evaluierung) und das Governance-Defizit (nur 21% der Unternehmen haben ein ausgereiftes Agent-Governance-Modell laut Deloitte) zeigen ein Feld, das schneller deployt als es verifiziert.
Drei Entwicklungen sind für den DACH-Raum besonders relevant:
Der Evaluierungs-Tooling-Markt wird explodieren. Wenn 89% der Teams Observability haben, aber nur 52% evaluieren, wartet eine massive Lücke auf bessere Werkzeuge. LangSmith, Braintrust, Cleanlab und eine Welle von Startups werden 2026 hart um Agent-Evaluierung konkurrieren.
Coding-Agenten werden die Messung von “KI-Agent-Adoption” verändern. Sie sind bereits die meistgenutzten täglichen Agenten mit großem Abstand, tauchen aber in den meisten Enterprise-Deployment-Zahlen nicht auf. Sobald Unternehmen Developer-Tool-Nutzung als KI-Agent-Adoption erfassen, werden sich die Schlagzeilen-Zahlen ändern.
Die Governance-Abrechnung kommt. PwC berichtet, dass 78% der Organisationen die Autonomie ihrer Agenten im nächsten Jahr erhöhen wollen. Aber nur 21% haben dafür Governance-Modelle parat. Diese Lücke wird die erste Welle hochkarätiger Agent-Ausfälle in regulierten Branchen produzieren. Für DACH-Unternehmen unter EU AI Act und DSGVO ist das Risiko doppelt: nicht nur Reputationsschaden, sondern auch regulatorische Konsequenzen.
Agent Engineering ist keine Nischendisziplin mehr. Es ist ein Fachgebiet mit eigenen Umfragedaten, eigenen Fehlermustern und einem sich rapide formierenden Set von Best Practices. Die Teams, die es als solches behandeln, die in Evaluierung neben Observability investieren, in Governance neben Deployment, werden diejenigen sein, die in einem Jahr noch Agenten in Produktion betreiben.
Häufig gestellte Fragen
Wie viele Teams haben KI-Agenten 2026 in Produktion?
57,3% der von LangChain befragten Teams betreiben KI-Agenten in Produktion, ein Anstieg von 51% im Vorjahr. G2 bestätigt diese Zahl unabhängig mit ebenfalls 57% Produktionsadoption bei Enterprise-Befragten.
Was ist die größte Hürde beim KI-Agent-Deployment?
Qualität und unzuverlässige Performance bleiben mit 32% die Hauptbarriere laut LangChains State of Agent Engineering Survey. Halluzinationen und inkonsistente Ausgaben werden am häufigsten als Qualitätsproblem genannt. Latenz ist mit 20% als neues großes Problem aufgetaucht, während Kostenbedenken dank günstigerer Modelle deutlich gesunken sind.
Wie viele Teams evaluieren ihre KI-Agenten?
Nur 52,4% der Teams führen Offline-Evaluierungen an Testdatensätzen durch und 37,3% betreiben Online-Evaluierung der Echtzeit-Performance. 29,5% der Teams evaluieren überhaupt nicht. Das steht in starkem Kontrast zur Observability-Adoption von 89% und offenbart eine deutliche Lücke zwischen Beobachten und Testen.
Welche KI-Agent-Use-Cases sind 2026 am populärsten?
Recherche und Zusammenfassung führt mit 58%, gefolgt von persönlicher Produktivität (53,5%) und Kundenservice (45,8%). Die Freitextantworten zeigen jedoch, dass Coding-Agenten (Claude Code, Cursor, GitHub Copilot) die mit Abstand meistgenutzten täglichen Agenten sind, obwohl sie nicht an der Spitze der offiziellen Kategorien stehen.
Was ist Agent Engineering als Disziplin?
Agent Engineering ist eine aufkommende Disziplin, die Produktdenken, Softwareentwicklung und Data Science vereint, um KI-Agent-Systeme zu bauen und zu betreiben. Der Fokus liegt auf der iterativen Verfeinerung nicht-deterministischer Systeme, einschließlich Evaluierung, Observability, Governance und Produktionsdeployment autonomer KI-Agenten.